Assuming the standard signal-plus-Gaussian-noise model we obtain for a complete sample
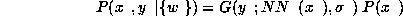
where 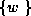 is the set of weights in the network.
For an incomplete sample
is the set of weights in the network.
For an incomplete sample
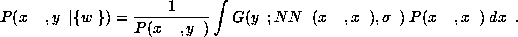
Using the same approximation as in Section 2.2,
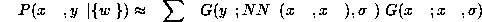
where 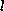 sums over all complete samples. As before, we substitute for the missing components the ones from the complete training data. The
log-likelihood
sums over all complete samples. As before, we substitute for the missing components the ones from the complete training data. The
log-likelihood 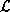 (a function of the network weights )
can be calculated as (
(a function of the network weights )
can be calculated as ( can be either complete or incomplete)
can be either complete or incomplete)
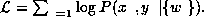 The maximum likelihood solution consists of finding weights which
maximize the log-likelihood. Using the approximation of Equation 1, we obtain for an incomplete
sample as gradient Equation 3
(compare Tresp, Ahmad and Neuneier, 1994).
The maximum likelihood solution consists of finding weights which
maximize the log-likelihood. Using the approximation of Equation 1, we obtain for an incomplete
sample as gradient Equation 3
(compare Tresp, Ahmad and Neuneier, 1994).